Scrapy框架(一):基本使用
前言
本篇文章简单介绍一下Scrapy框架的基本使用方法,以及在使用过程中遇到的一些问题和解决方案。
Scrapy框架的基本使用
环境的安装
1.输入下述指令安装wheel
1 | pip install wheel |
2.下载twisted
这里提供一个下载链接:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
注:这里下载有两点需要注意:
- 要下载与自己python版本相对应的文件,
cpxx为版本号。(例如我的python版本为3.8.2,就下载cp38的文件)- 根据操作系统位数下载对应文件。32位操作系统下载
win32;64位操作系统下载win_amd64。
3.安装twisted
在上一步下载好的twisted的目录下输入下面的命令:
1 | pip install Twisted-20.3.0-cp38-cp38-win_amd64.whl |
4.输入下述指令安装pywin32
1 | pip install pywin32 |
5.输入下述指令安装scrapy
1 | pip install scrapy |
6.测试
在终端里输入scrapy命令,没有报错即表示安装成功。
创建scrapy工程
这里是在PyCharm中创建的scrapy工程
1.打开Terminal面板,输入下述指令创建一个scrapy工程
1 | scrapy startproject ProjectName |
ProjectName为项目名称,自己定义。
2.自动生成如下目录
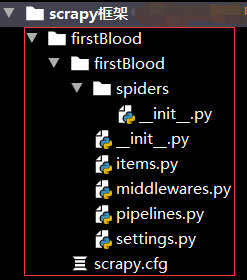
3.创建一个爬虫文件
首先进入刚刚创建的工程目录下:
1 | cd ProjectName |
然后在spiders子目录中创建一个爬虫文件
1 | scrapy genspider spiderName www.xxx.com |
spiderName为爬虫文件名称,自己定义。
4.执行工程
1
scrapy crawl spiderName
1 | scrapy crawl spiderName |
文件参数的修改
为了能更好的执行爬虫项目,需要修改一些文件的参数。
1.spiderName.py
该爬虫文件的内容如下:
1 | import scrapy |
注:
allowed_domains列表用来限定请求的url。一般情况不需要,将其注释掉即可。
2.settings.py
1). ROBOTSTXT_OBEY
找到ROBOTSTXT_OBEY关键字,此处默认参数为Ture。(即项目默认遵守robots协议)为了项目练习,可以暂时将其改为False。
1 | # Obey robots.txt rules |
2). USER_AGENT
找到USER_AGENT关键字,此处默认注释掉了。修改其内容,以避免UA反爬。
1 | # Crawl responsibly by identifying yourself (and your website) on the user-agent |
3). LOG_LEVEL
为了更清晰的查看项目运行结果(项目默认运行结果会打印大量的日志信息),可以手动添加LOG_LEVEL关键字。
1
2
# 显示指定类型的日志信息
LOG_LEVEL = 'ERROR' # 只显示错误信息
1 | # 显示指定类型的日志信息 |
可能遇到的问题
1.成功安装完scrapy,但是在创建爬虫文件后依然显示import scrapy有误。
本人练习时用的环境都是基于Python3.8创建的各种虚拟环境,然而在搭建scrapy项目时pip install scrapy始终报错。
最初手动在官网:https://scrapy.org/ 下载scrapy库,然后安装到虚拟环境的site-packages目录下,果然回头看import scrapy显示正常了,程序也可以跑。但是依然打印大量的错误信息,通过PyCharm的Python Interpreter查看并没有Scrapy库在内。
无奈又尝试了一些解决方案,无果…
最后发现Anaconda自带Scrapy库,于是又基于Anaconda创建了一个虚拟环境,完美运行~~~~
结尾
好好学习
 微信
微信 支付宝
支付宝
