前言
以爬取github信息为例,介绍Scrapy框架用法。
目标:根据github关键词搜索,爬取所有检索结果。具体包括名称 、链接 、stars 、Updated 、About 信息。
项目创建
开启Terminal面板,创建一个名为powang的scrapy的工程:
1 scrapy startproject powang
进入创建的工程目录下:
在spiders子目录中创建一个名为github的爬虫文件:
1 scrapy genspider github www.xxx.com
说明:网址可以先随便写,具体在文件中会修改
执行爬虫命令:
如本项目执行命令:scrapy crawl github
项目分析与编写
settings
首先看配置文件,在编写具体的爬虫前要设置一些参数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 ROBOTSTXT_OBEY = False LOG_LEVEL = 'ERROR' USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.56' DOWNLOADER_MIDDLEWARES = { 'powang.middlewares.PowangDownloaderMiddleware' : 543 , } ITEM_PIPELINES = { 'powang.pipelines.PowangPipeline' : 300 , } RETRY_TIMES = 100 RETRY_ENABLED = True RETRY_HTTP_CODES = [500 , 503 , 504 , 400 , 403 , 408 , 429 ] DOWNLOAD_DELAY = 2 RANDOMIZE_DOWNLOAD_DELAY = True
说明:
ROBOTSTXT_OBEY:默认遵守robots协议,很多网站都有该协议(为了防止爬虫对不必要信息的爬取)。这里为了项目测试,选择关闭(False)LOG_LEVEL:设置日志打印等级,这里设置为仅打印错误类型日志信息。(需要手动添加)USER_AGENT:在请求头中添加UA信息,用于跳过UA拦截。也可以直接在中间件中配置UA池(更推荐后者)DOWNLOADER_MIDDLEWARES:开启下载中间件。在middlewares.py(中间件)中会设置诸如UA池、IP池等配置。ITEM_PIPELINES:用于开启item配置。(下文会讲到关于item的作用)请求重试(scrapy会自动对失败的请求发起新一轮尝试):
RETRY_TIMES:设置最大重试次数。在项目启动后,如果在设定重试次数之内还无法请求成功,则项目自动停止。RETRY_ENABLED:失败请求重试(默认开启)RETRY_HTTP_CODES:设定针对特定的错误代码发起重新请求操作
下载延时:
DOWNLOAD_DELAY:设置发送请求的延时RANDOMIZE_DOWNLOAD_DELAY:设置随机请求延时
配置管道以及中间件的数字表示优先级,数值越小,优先级越高。
爬虫文件
默认文件如下:
1 2 3 4 5 6 7 8 9 import scrapyclass GithubSpider (scrapy.Spider ): name = 'github' allowed_domains = ['www.xxx.com' ] start_urls = [] def parse (self, response ): pass
说明:
name:爬虫文件的名称,即爬虫源文件的一个唯一标识allowed_domains:用来限定start_urls列表中哪些url可以进行请求发送(通常不会使用)start_urls:起始的url列表。该列表中存放的url会被scrapy自动进行请求的发送(可以设置多个url)parse:用于数据解析。response参数表示的就是请求成功后对应的响应对象(之后就是直接对response进行操作)
分析:
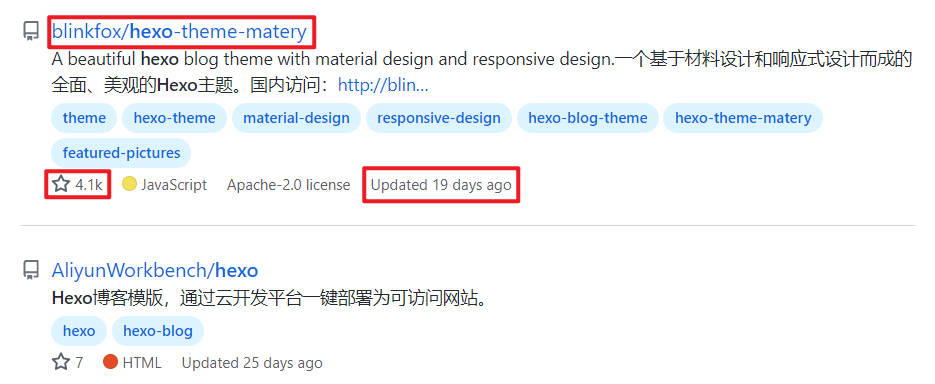
以搜索结果hexo为例:
每一条结果的名称 及链接 、stars 以及Updated 都是可以在搜索页直接获取的,
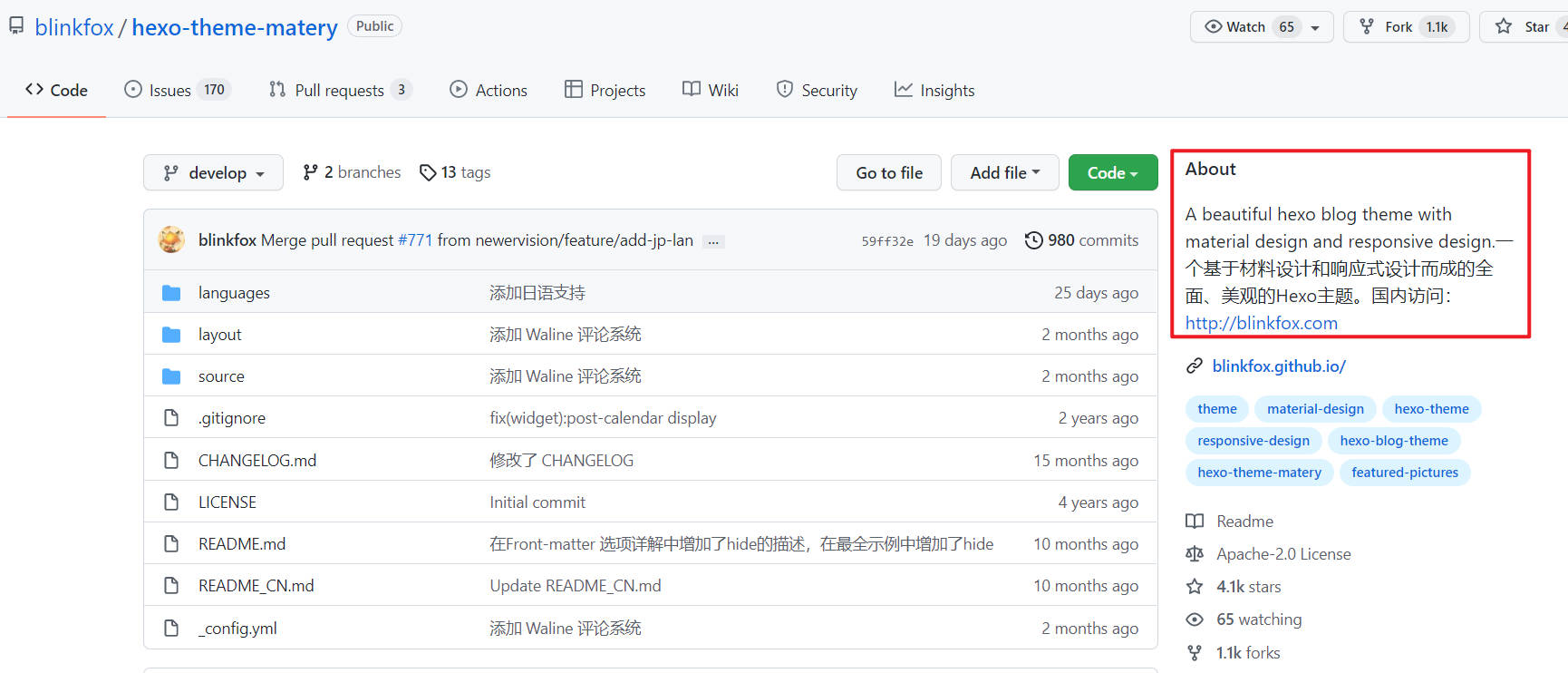
但是有些过长的About 信息在搜索页展示并不全,只得通过点击详情页进行获取。
以及最后要爬取全部信息,需要分页爬取。
代码编写
首先编写一个起始的url和一个用于分页通用的url模板:
1 2 3 4 5 6 7 8 9 10 keyword = 'vpn' pageNum = 1 start_urls = ['https://github.com/search?q={keyword}&p={pageNum}' .format (keyword=keyword, pageNum=pageNum)] url = 'https://github.com/search?p=%d&q={}' .format (keyword)
编写parse函数(搜索结果页面分析):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 def parse (self, response ): status_code = response.status page_text = response.text tree = etree.HTML(page_text) li_list = tree.xpath('//*[@id="js-pjax-container"]/div/div[3]/div/ul/li' ) for li in li_list: item = PowangItem() item_name = li.xpath('.//a[@class="v-align-middle"]/@href' )[0 ].split('/' , 1 )[1 ] item['item_name' ] = item_name item_link = 'https://github.com' + li.xpath('.//a[@class="v-align-middle"]/@href' )[0 ] item['item_link' ] = item_link item_updated = li.xpath('.//relative-time/@datetime' )[0 ].replace('T' , ' ' ).replace('Z' , '' ) item_updated = str (datetime.datetime.strptime(item_updated, '%Y-%m-%d %H:%M:%S' ) + datetime.timedelta(hours=8 )) item['item_updated' ] = item_updated try : item_stars = li.xpath('.//a[@class="Link--muted"]/text()' )[1 ].replace('\n' , '' ).replace(' ' , '' ) item['item_stars' ] = item_stars except IndexError: item_stars = 0 item['item_stars' ] = item_stars else : pass yield scrapy.Request(item_link, callback=self.items_detail,meta={'item' :item}) new_url = format (self.url % self.pageNum) print("===================================================" ) print("第" + str (self.pageNum) + "页:" + new_url) print("状态码:" + str (status_code)) print("===================================================" ) self.pageNum += 1 yield scrapy.Request(new_url, callback=self.parse)
说明:
response.status:可以获取响应状态码
为了后期对爬取到的数据进行进一步操作(如:存储),需要将每一条数据进行item对象的封装
1 2 3 4 5 6 7 8 item = PowangItem() item['item_name' ] = item_name item['item_link' ] = item_link item['item_updated' ] = item_updated item['item_stars' ] = item_stars
yield:
为了获取About内容,需要对爬取到的url再进行访问以获取到详情页面,这时就可以使用yield发送访问请求:
格式:yield scrapy.Request(url, callback=xxx,meta={'xxx':xxx})
1 yield scrapy.Request(item_link, callback=self.items_detail,meta={'item' :item})
url:即详情页的url
callback:回调函数(可以编写其他函数,也可以是自己(递归))。即携带url发起请求,并交给回调函数进行处理,在其中的response处理信息
meta:字典形式,可以将该函数中的item对象继续交由下一个回调函数进行下一步处理
分页操作:利用yield递归式发起请求,处理不同页面的数据
编写items_detail函数(结果详情页分析):
为了获取About信息,需要对搜索结果的详情页进行分析。
1 2 3 4 5 6 7 8 9 10 11 12 def items_detail (self, response ): item = response.meta['item' ] page_text = response.text tree = etree.HTML(page_text) item_describe = '' .join(tree.xpath('//*[@id="repo-content-pjax-container"]/div/div[3]/div[2]/div/div[1]/div/p//text()' )).replace('\n' , '' ).strip().rstrip(); item['item_describe' ] = item_describe yield item
说明:
利用response.meta['xxx']可以接收上一个函数传来的参数(如:接收item)
如果在经过一系列回调函数操作后对item对象封装完毕,在最后一个函数需要利用yield将item交由给管道处理
完整的爬虫文件如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 import datetimefrom lxml import htmletree = html.etree import scrapyfrom powang.items import PowangItemclass GithubSpider (scrapy.Spider ): name = 'github' keyword = 'hexo' pageNum = 1 start_urls = ['https://github.com/search?q={keyword}&p={pageNum}' .format (keyword=keyword, pageNum=pageNum)] url = 'https://github.com/search?p=%d&q={}' .format (keyword) def parse (self, response ): status_code = response.status page_text = response.text tree = etree.HTML(page_text) li_list = tree.xpath('//*[@id="js-pjax-container"]/div/div[3]/div/ul/li' ) for li in li_list: item = PowangItem() item_name = li.xpath('.//a[@class="v-align-middle"]/@href' )[0 ].split('/' , 1 )[1 ] item['item_name' ] = item_name item_link = 'https://github.com' + li.xpath('.//a[@class="v-align-middle"]/@href' )[0 ] item['item_link' ] = item_link item_updated = li.xpath('.//relative-time/@datetime' )[0 ].replace('T' , ' ' ).replace('Z' , '' ) item_updated = str (datetime.datetime.strptime(item_updated, '%Y-%m-%d %H:%M:%S' ) + datetime.timedelta(hours=8 )) item['item_updated' ] = item_updated try : item_stars = li.xpath('.//a[@class="Link--muted"]/text()' )[1 ].replace('\n' , '' ).replace(' ' , '' ) item['item_stars' ] = item_stars except IndexError: item_stars = 0 item['item_stars' ] = item_stars else : pass yield scrapy.Request(item_link, callback=self.items_detail,meta={'item' :item}) new_url = format (self.url % self.pageNum) print("===================================================" ) print("第" + str (self.pageNum) + "页:" + new_url) print("状态码:" + str (status_code)) print("===================================================" ) self.pageNum += 1 yield scrapy.Request(new_url, callback=self.parse) def items_detail (self, response ): item = response.meta['item' ] page_text = response.text tree = etree.HTML(page_text) item_describe = '' .join(tree.xpath('//*[@id="repo-content-pjax-container"]/div/div[3]/div[2]/div/div[1]/div/p//text()' )).replace('\n' , '' ).strip().rstrip(); item['item_describe' ] = item_describe yield item
item
在item提交给管道前,需要先定义字段:
1 2 3 4 5 6 7 8 9 import scrapyclass PowangItem (scrapy.Item ): item_name = scrapy.Field() item_link = scrapy.Field() item_describe = scrapy.Field() item_stars = scrapy.Field() item_updated = scrapy.Field() pass
说明:
为了将爬取到的数据更为规范化的传递给管道进行操作,Scrapy为我们提供了Item类。相比于字典(它有点类似与字典)来说更加规范化且更为简洁。
pipelines
对parse传递来的数据进行存储等操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 import csvimport osfrom itemadapter import ItemAdapterclass PowangPipeline : file = None def open_spider (self,spider ): path = './data' isExist = os.path.exists(path) if not isExist: os.makedirs(path) print("开始爬取并写入文件...." ) self.file = open (path + '/github.csv' ,'a' , encoding='utf_8_sig' , newline="" ) def process_item (self, item, spider ): item_name = item['item_name' ] item_link = item['item_link' ] item_describe = item['item_describe' ] item_stars = item['item_stars' ] item_updated = item['item_updated' ] fieldnames = ['item_name' , 'item_link' , 'item_describe' , 'item_stars' , 'item_updated' ] w = csv.DictWriter(self.file, fieldnames=fieldnames) w.writerow(item) return item def close_spider (self,spider ): print('爬取结束....' ) self.file.close()
说明:
open_spider():在爬虫开始前执行唯一一次(需要自行重写该方法)process_item():用于处理parse传来的item对象。该方法每接收一个item就会被调用一次close_spider():在爬虫结束后执行唯一一次(需要自行重写该方法)return item:管道类可以编写多个,用以对parse传来的item对象进行不同的操作。而item的传递顺序就是类编写的顺序,通过return item可以将item对象传递给下一个即将被执行的管道类
这里将数据保存至csv文件中。
middlewares
中间件可用于对请求(包括异常请求)进行处理。
直接关注PowangDownloaderMiddleware类(XXXDownloaderMiddleware):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 class PowangDownloaderMiddleware : user_agent_list = [ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 " "(KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1" , "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 " "(KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11" , "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 " "(KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6" , "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 " "(KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6" , "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 " "(KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1" , "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 " "(KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5" , "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 " "(KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5" , "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3" , "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3" , "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3" , "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3" , "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3" , "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3" , "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3" , "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3" , "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3" , "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 " "(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24" , "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 " "(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24" ] Proxys=['127.0.0.1:1087' ] @classmethod def from_crawler (cls, crawler ): s = cls() crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) return s def process_request (self, request, spider ): request.headers['User-Agent' ] = random.choice(self.user_agent_list) proxy = random.choice(self.Proxys) request.meta['proxy' ] = proxy return None def process_response (self, request, response, spider ): return response def process_exception (self, request, exception, spider ): pass def spider_opened (self, spider ): spider.logger.info('Spider opened: %s' % spider.name)
说明:
process_request():用于拦截请求,可设置UA或IP等信息
由于本项目访问github,国内ip不稳定,因此开启代理(本地)
process_response():用于拦截响应
process_exception():用于拦截发生异常的请求
至此,键入启动命令可以运行项目。
后记
难度不大。
(去年学习的scrapy,一直搁置着没做记录,也就忘了。正好最近项目需要又重新捡了起来)
 微信
微信 支付宝
支付宝