JavaScript学习笔记(ES6+)
前言
针对ES6+的一些设计进行学习,感觉知识点很杂,故进行一个梳理和记录。
作用域
作用域(scope)规定了变量能够被访问的“范围”,离开了这个“范围”变量便不能被访问,作用域分为全局作用域和局部作用域。
全局作用域
在.html文件中,<script> 标签的最外层就是全局作用域,在此声明的变量在函数内部也可以被访问。
1 | <script> |
在.js 文件中,最外层就是就是全局作用域,在此声明的变量在函数内部也可以被访问。
1 | const name = '花猪'; //全局变量(在全局作用域中) |
注:该函数的写法为立即执行函数(匿名函数),其语法有以下两种方式:
(function () { console.log('此处为函数体') })();(function () { console.log('此处为函数体') } ());必须有分号
;
局部作用域
局部作用域进一步被分为函数作用域和块作用域。
-
函数作用域
在函数内部声明的变量只能在函数内部被访问,外部无法直接访问。
1
2
3
4
5
6
7
8
9function count(x, y) {
//函数作用域
var res = x + y //函数内部声明的变量
console.log(res)
}
count(10, 8) //18
console.log(res) //报错 -
块作用域
使用
{}包裹的代码称为代码块,代码块内部声明的变量外部无法直接访问。1
2
3
4
5
6
7{
//块作用域
let name = '花猪' //代码块内部声明的变量
console.log(name) //花猪
}
console.log(name) //报错注:
- 块作用域的例子:
if()、for()…中的{}均为块作用域 - 块作用域是函数作用域的子集
- 块作用域的例子:
var、let和const
-
var-
var声明的范围是函数作用域,这意味着在块作用域外也可以访问到其声明的内容1
2
3
4if(true) {
var name = '花猪'
}
console.log(name) //花猪在函数作用域外无法访问
1
2
3
4function sayHi() {
var name = '花猪'
}
console.log(name) //报错:name is not defined -
用
var定义一个变量后,可以不初始化,其值为undefined -
var赋值不仅可以改变保存的值,还可以改变值的类型1
2
3var age = 18
age = '花猪'
console.log(age) //花猪 -
var存在声明提升:所有被var声明的变量会被拉到函数作用域的顶部。1
2
3
4(function () {
console.log(age)
var age = 18
})()上述代码不会报错,因为ECMAScript运行时把它看成等价于如下代码:
1
2
3
4
5(function () {
var age
console.log(age)
age = 18
})()仅
var存在声明提升。 -
var在全局作用域中声明的变量会成为window对象的属性(这一点与let不同)1
2
3
4<script>
var name = '花猪'
console.log(window.name) //花猪
</script>
-
-
let-
let声明的范围是块作用域1
2
3
4if(true) {
let name = '花猪'
}
console.log(name) //报错:name is not defined -
let在全局作用域中声明的变量不会成为window对象的属性(这一点与var不同)1
2
3
4<script>
let name = '花猪'
console.log(window.name) //undefined
</script>
-
-
const-
const与let基本相同,唯一区别是const声明变量时必须赋值(初始化),且该变量不可修改1
2const age = 18
age = 20 //报错:给常量赋值
-
声明原则:
-
尽量不使用
var -
const优先,let次之 -
可以不使用任何关键字在函数作用域内声明一个全局变量,但不推荐这么做。
1
2
3
4(function () {
name = '花猪' //定义全局变量
})()
console.log(name) //花猪
作用域链
作用域链本质上是底层的变量查找机制。
- 在函数被执行时,会优先在当前函数作用域中查找变量
- 如果当前作用域查找不到则会逐级查找父级作用域直到全局作用域
1 | // 全局作用域 |
关于作用域链:
- 嵌套关系的作用域串联起来形成了作用域链
- 相同作用域链中按着从小到大的规则查找变量
- 子作用域能够访问父作用域,父级作用域无法访问子级作用域
垃圾回收机制
垃圾回收机制(Garbage Collection),简称GC。
-
垃圾回收的基本思路:确定哪个变量不会再使用,然后释放它的内存。
-
垃圾回收的过程是周期性的。即垃圾回收程序每隔一定时间(或者说在代码执行过程中某个预定的收集时间)就会自动运行。
JavaScript内存的生命周期:
- 内存分配:当声明变量、函数、对象的时候,系统会自动为他们分配内存
- 内存使用:即读写内存,也就是使用变量、函数等
- 内存回收:使用完毕,由垃圾回收自动回收不再使用的内存
说明:
- 全局变量一般不会回收(关闭页面回收);
- 一般情况下局部变量的值, 不用了, 会被自动回收掉
-
垃圾回收机制的两个算法:
-
引用计数法(已淘汰):定义“内存不再使用”,就是看一个对象是否有指向它的引用,没有引用了就回收对象
- 跟踪记录被引用的次数
- 如果被引用了一次,那么就记录次数1,多次引用会累加
- 如果减少一个引用就减1
- 如果引用次数是0 ,则释放内存
-
标记清除法
-
标记清除算法将“不再使用的对象”定义为“无法达到的对象”。
-
就是从根部(在JS中就是全局对象)出发定时扫描内存中的对象。 凡是能从根部到达的对象,都是还需要使用的。
-
那些无法由根部出发触及到的对象被标记为不再使用,稍后进行回收。
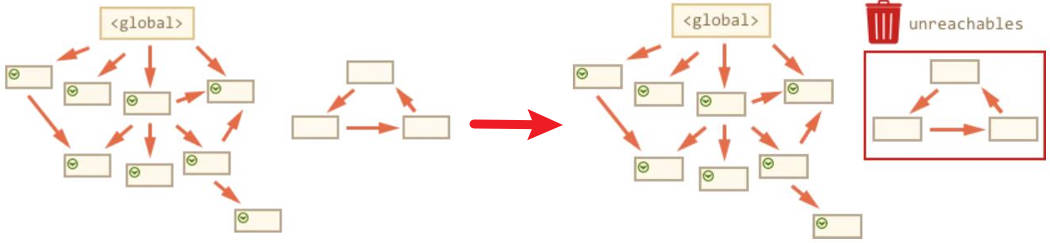
-
-
如果不再用到的内存没有及时释放,就叫做内存泄漏。
闭包
-
概念:一个函数对周围状态的引用捆绑在一起,内层函数中访问到其外层函数的作用域。
简单理解:闭包 = 内层函数 + 外层函数的变量
-
闭包的基本格式:
1
2
3
4
5
6
7
8
9function outer() {
let a = 1
function fn() {
console.log(a)
}
return fn //必须得返回函数。(不能是fn(),它表示立即执行)
}
const execute = outer()
execute() //调用注意:这里
let a = 1和function fn()构成闭包范围化简写法:
1
2
3
4
5
6
7
8function outer() {
let a = 1
return function() { //必须得返回函数。(不能是fn(),它表示立即执行)
console.log(a)
}
}
const execute = outer()
execute() //调用 -
闭包的作用:封闭数据,提供操作,外部也可以访问函数内部的变量。
-
闭包的应用:实现数据的私有。
案例:函数计数器。
如果想统计一个函数的调用次数,可以使用以下方式:
1
2
3
4
5let count = 0
function fn() {
count++
console.log(`函数被调用${count}次`)
}但是这种方式会出现问题,即
count作为全局变量被暴露在外,容易被篡改1
2
3
4
5
6
7fn()
函数被调用1次
fn()
函数被调用2次
count = 999
fn()
函数被调用1000次这显然不是期望的结果,那么如何将
count被保护起来,使其除了fn()函数无法被篡改。可以通过闭包的方式实现:1
2
3
4
5
6
7
8
9
10function fn() {
let count = 0
function fun() {
count++
console.log(`函数被调用${count}次`)
}
return fun
}
const execute = fn()1
2
3
4
5
6
7execute()
函数被调用1次
execute()
函数被调用2次
count = 999
execute()
函数被调用3次这里
count = 999实际上是重新声明了一个全局变量。 -
闭包可能引起内存泄漏(分析上面的例子)
正常情况下,变量
count为fn()函数作用域中的变量,当调用fn()之后,应该被回收,但是上述案例由于闭包的设计:首先变量execute为全局变量,除关闭的情况下不会被回收,但是execute调用fn(),而fn()返回fun(),这就导致全局变量execute可以指向fun(),而fun()使用了变量count,所以按照标记清除法,从全局(global)可以指向变量count,因此count不会被回收,导致内存泄漏。
函数
函数提升
函数提升类似于var声明的变量提升,是指函数在声明之前即可被调用。(函数提升出现在相同作用域当中)
1 | // 调用函数 |
但是函数表达式不存在提升现象
1 | bar() // 错误 |
函数参数
默认值
声明函数时为形参赋值即为参数的默认值,如果参数未自定义默认值时,参数的默认值为 undefined,调用函数时没有传入对应实参时,参数的默认值被当做实参传入。
1 | function sum(x = 0, y = 0) { |
参数扩展与收集
如果遇到不定参数的情况,可以使用动态参数和剩余参数。
动态参数
arguments 是函数内部内置的伪数组变量,它包含了调用函数时传入的所有实参。可以通过下标访问的方式得到传入函数的实参。
1 | function sum() { // 形参可以写,也可以不写 |
因为
arguments是一个伪数组,因此不可直接进行迭代,如果需要,可以将arguments对象转换为数组再进行迭代:
2
3
4
5
6
7
8
9
10
11
12
13
14
let result = 0
const arr = Array.from(arguments) // 方式一
// const arr = [...arguments] //方式二
arr.forEach(function(item, index) {
result += item
console.log(item)
console.log(index)
})
console.log(result)
}
sum() // 0
sum(4, 6) // 10
剩余参数
可以借助展开运算符...实现剩余参数。剩余参数应该置于函数形参的末尾处,用于获取多余的实参,它是一个真数组(Array实例)。
扩展:展开运算符
...最主要的作用就是展开数组
2
3
// 展开运算符 可以展开数组
console.log(...arr) //1 2 3虽然输出为
1 2 3,但实际上...arr等价于1,2,3应用:合并数组:
2
3
4
5
6
7
8
9
10
console.log(arguments.length)
}
let arr = [1, 2, 3]
count(-1, ...arr) // 4
count(...arr, 5) // 4
count(-1, ...arr, 5) // 5
count(...arr, ...[5, 6, 7]) // 6
1 | function sum(x = 0, y = 0, ...arr) { |
剩余参数并不影响
arguments的使用:
2
3
4
5
6
7
8
let result = x + y
arr.forEach(item => {
result += item
})
console.log(result)
console.log(arguments.length) // 输出参数的总数
}
在实际开发中,通常使用剩余参数。
箭头函数
基本语法格式:
1 | const sum = (x, y) => { |
当只有一个参数的时候,参数括号()可以省略:
1 | const square = x => { |
记忆:没有参数和多参数的时候需要括号。
当函数体只有一行代码时,可以省略函数体的大括号{}:
1 | const square = x => console.log(x * x) |
当函数体只有一行代码时,可以省略return:
1 | const square = x => x * x |
加括号的函数体返回对象字面量表达式,即箭头函数可以直接返回一个对象:
1 | const person = (name, age) => ({ Name: name, Age: age}) |
理解:上述代码的大括号可以理解为对象(object)的大括号,但是为了不让ECMAScript混淆,需要在对象外用小括号包
()起来。
-
箭头函数没有
arguments动态参数,但可以使用剩余参数:1
2
3
4
5
6
7
8const sum = (...arr) => {
let result = 0
for (let i = 0; i < arr.length; i++) {
result += arr[i]
}
console.log(result)
}
sum(4, 6) // 10 -
箭头函数不会创建自己的
this,它只会从自己的作用域链的上一层沿用this(可以理解为箭头函数的this实际上调用的是父级的this)1
2
3
4
5
6
7
8
9
10
11
12
13const person = {
Name: '花猪',
Age: 18,
saySomething: function (words) {
console.log(this) // { Name: '花猪', Age: 18, saySomething: [Function: saySomething] }
const say = () => {
console.log(`${this.Name}说:${words}`)
console.log(this) // { Name: '花猪', Age: 18, saySomething: [Function: saySomething] }
}
say()
}
}
person.saySomething('你好') // 花猪说:你好如果使用DOM事件回调函数,箭头函数的
this为全局的window,因此操作DOM时不推荐使用箭头函数。
解构赋值
解构赋值是一种快速为变量赋值的简洁语法,本质上仍然是为变量赋值,分为数组解构、对象解构两大类型。
数组解构
数组解构可以将数组的单元值快速批量赋值给一系列变量,语法如下述代码所示:
1 | let arr = [1, 2, 3] |
声明和赋值可以合并:
2
3
4
console.log(a); // 1
console.log(b); // 2
console.log(c); // 3
-
变量的数量大于单元值数量时,多余的变量将被赋值为
undefined1
2
3
4let [a, b, c] = [1, 2]
console.log(a); // 1
console.log(b); // 2
console.log(c); // undefined为了防止
undefined的出现,可以设置参数默认值:1
2
3
4let [a = 0, b = 0, c = 0] = [1]
console.log(a); // 1
console.log(b); // 0
console.log(c); // 0 -
变量的数量小于单元值数量时,可以通过展开运算符
...获取剩余单元值,但只能置于最末位1
2
3
4
5
6let [a, b, c, ...arr] = [1, 2, 3, 4, 5]
console.log(a); // 1
console.log(b); // 2
console.log(c); // 3
console.log(arr[0]) // 4
console.log(arr[1]) // 5 -
可以按需赋值:
1
2
3
4let [a, b, , d] = [1, 2, 3, 4]
console.log(a) // 1
console.log(b) // 2
console.log(d) // 4 -
可以结构多维数组:
1
2
3
4
5
6const [a, b, c] = [1, 2, [3, 4]]
console.log(a) // 1
console.log(b) // 2
console.log(c) // [3,4]
console.log(c[0]) // 3
console.log(c[1]) // 41
2
3
4
5const [a, b, [c, d]] = [1, 2, [3, 4]]
console.log(a) // 1
console.log(b) // 2
console.log(c) // 3
console.log(d) // 4
对象解构
对象解构可以将对象属性和方法快速批量赋值给一系列变量,语法如下述代码所示:
1 | const person = { |
注意:对象结构的变量名必须和对象中的属性名和方法名一致
-
对象中找不到与变量名一致的属性时变量值为
undefined,允许初始化变量赋默认值:1
2
3
4
5
6
7
8
9const person = {
}
const {Name = '张三', Age = '20', sayHi = () => {console.log('Hello')}} = person
console.log(Name) // 张三
console.log(Age) // 20
sayHi() // Hello -
支持多维解构赋值:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15const person = {
Name: '花猪',
Age: 18,
Addr: {
Province: '四川',
City: '成都',
}
}
const {Name, Age, Addr: {Province, City}} = person
console.log(Name) // 花猪
console.log(Age) // 18
console.log(Province) // 四川
console.log(City) // 成都
下面以常用的JSON数据为例进行解构:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
"code": 200,
"msg": "获取新闻列表成功",
"data": [
{
"id": 1,
"title": "5G商用自己,三大运用商收入下降",
"count": 58
},
{
"id": 2,
"title": "国际媒体头条速览",
"count": 56
},
{
"id": 3,
"title": "乌克兰和俄罗斯持续冲突",
"count": 1669
},
]
}
解构
msg对象,并赋值给函数receive():
2
3
4
5
6
console.log(code)
console.log(msg)
console.log(data)
}
receive(msg)为了避免变量名混淆,还可以起别名:
2
3
4
5
6
console.log(Mycode)
console.log(Mymsg)
console.log(Mydata)
}
receive(msg)
原型
构造函数
在介绍原型之前先来看一下JavaScript中的构造函数,JavaScript可以通过构造函数实现面向对象思想中的封装特性。
下面是构造函数的写法:
1 | function Animal(name) { |
构造函数在技术上相当于常规函数,为了区分,有几个约定:
- 构造函数的命名以大写字母开头。
- 创建实例对象的时候需要用
new关键字来执行,该过程被称为实例化。 - 构造函数内部无需写
return(返回值无效),构造函数会在实例化的过程中自动返回创建的对象。 - 实例成员:可以通过
this关键字添加实例对象的属性和方法,构造函数的this会指向新的实例化对象。 - 静态成员:可以通过
构造函数名.属性或构造函数名.方法的方式创建构造函数的属性和方法,静态成员方法中的this会指向构造函数本身。
上述例子的构造函数方法很好用,但是在具体使用中会存在浪费内存的问题,参考下面的案例:
1 | function Animal(name) { |
所有动物(Animal)都有sleep方法,但是由于该sleep方法是实例成员,因此cat.sleep跟dog.sleep不同,这就会导致每次实例化一个Animal对象,相应的都会为一个sleep方法开辟一块内存空间。但实际上不希望如此,我们希望将共有的东西抽取出来,以上述案例为例:我们更希望为sleep方法只开辟一块内存空间,以后所有的实例对象调用此方法都会指向该地址,这样可以节省内存。
原型对象 prototype
(事实上,构造函数中的公共方法是通过原型进行函数分配的,这可以解决上述案例中浪费内存的问题。)
JavaScript规定,每一个构造函数都有一个prototype属性,指向另一个对象,被称为原型对象。在对象实例化的过程中不会多次创建原型上的函数,因此可以将公共的方法直接定义在原型对象(prototype)上,所有的实例对象可以共享这些方法。
可以通过构造函数名.prototype.方法为原型对象添加方法,可以通过实例对象调用该方法,下面来看具体用法:
1 | function Animal(name) { |
同构造函数中的this一样,原型对象中的this会指向新的实例化对象,因此cat.sleep跟dog.sleep相同。
constructor属性
在每个原型对象中都有一个constructor属性(constructor构造函数),该属性指向该原型对象的构造函数:
1 | function Animal(name) { |
利用constructor就可以通过原型对象找到该原型对象的构造函数。
至此可以找到一个双向关系:
- 构造函数通过
prototype找到该构造函数的原型对象- 原型对象通过
constructor找到该原型对象的构造函数
分析如下应用场景:想要为Animal构造函数添加多个共享方法,有下面两种选择:
-
通过
Animal.prototype.方法在Animal的原型对象上逐个添加方法:1
2
3
4
5
6
7
8
9
10
11function Animal(name) {
this.name = name
}
Animal.prototype.sleep = function () {
console.log(`${this.name} 正在睡觉`)
}
Animal.prototype.eat = function () {
console.log(`${this.name} 正在吃饭`)
}
// ...但是如果有很多方法,这样的写法代码冗余且不直观。
-
可以考虑给
prototype原型对象以对象赋值的形式统一添加多个方法:1
2
3
4
5
6
7
8
9
10
11
12
13function Animal(name) {
this.name = name
}
Animal.prototype = {
sleep: function () {
console.log(`${this.name} 正在睡觉`)
},
eat: function () {
console.log(`${this.name} 正在吃饭`)
},
// ...
}但是这种方式存在一个问题,原有的
prototype原型对象中包含constructor属性,它可以指向构造函数。但是通过上述方法,相当于创建了一个新的对象,把原有的prototype原型对象给覆盖掉了,这样就抹去了constructor属性,使得没有办法通过该原型对象找回构造函数了:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15function Animal(name) {
this.name = name
}
Animal.prototype = {
sleep: function () {
console.log(`${this.name} 正在睡觉`)
},
eat: function () {
console.log(`${this.name} 正在吃饭`)
},
}
console.log(Animal.prototype.constructor) // [Function: Object]
console.log(Animal.prototype.constructor === Animal) // false使用这种方式当然没有问题,只是我们还需要利用
constructor手动指回构造函数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16function Animal(name) {
this.name = name
}
Animal.prototype = {
constructor: Animal, // 利用constructor手动将该原型对象指回Animal
sleep: function () {
console.log(`${this.name} 正在睡觉`)
},
eat: function () {
console.log(`${this.name} 正在吃饭`)
},
}
console.log(Animal.prototype.constructor) // [Function: Animal]
console.log(Animal.prototype.constructor === Animal) // true
对象原型 _proto_
为什么实例对象可以访问到原型对象中的共有方法呢?因为在每个实例对象中都有一个__proto__属性,被称为对象原型,它可以指向创建该实例对象的构造函数的prototype原型对象。
对象原型 __proto__中同样包含constructor属性,指向构造函数。
1 | function Animal(name) { |
构造函数、原型对象、对象原型的关系
至此,我们可以画出构造函数、原型对象(prototype)以及对象原型(__proto__)三者之间的关系:
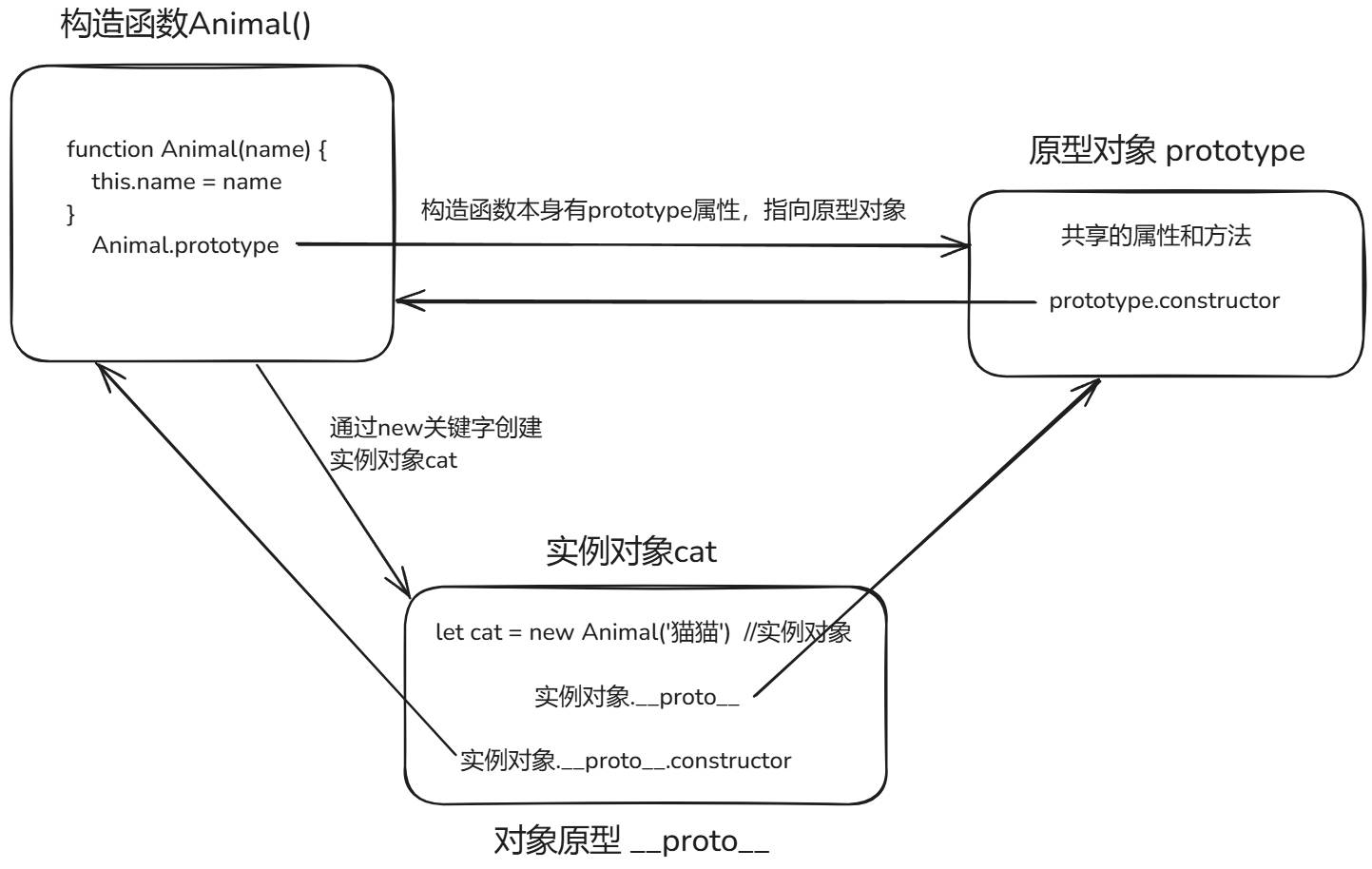
原型继承
可以通过子类.prototype = new 父类构造函数()的形式实现对象间的继承关系。
1 | function Animal(name) { |
原型链
基于原型对象的继承使得不同构造函数的原型对象关联在一起,并且这种关联的关系是一种链状的结构。将原型对
象的链状结构关系称为原型链。
1 | function Animal(name) { |
原型链的查找规则:
- 当访问一个对象的属性(包括方法)时,首先查找这个对象自身有没有该属性。
- 如果没有就查找它的原型(也就是
__proto__指向的prototype原型对象) - 如果还没有就查找原型对象的原型,以此类推直到找到
Object为止(null)
__proto__原型对象的意义就在于为对象成员查找机制提供一个方向,或者说一条路线。
可以使用instanceof运算符检测实例对象或者构造函数的prototype原型对象是否出现在某个实例对象的原型链上:
1 | function Animal(name) { |
深拷贝
注:浅拷贝和深拷贝只针对引用类型。
谈及深拷贝,肯定先介绍一下浅拷贝,可以使用Object.assign(target, source)方法将source浅拷贝至target,下面来看一个例子:
1 | // 声明一个person |
可以看到,这种方式成功修改了name、age、addr三个属性,但是在修改another的addr属性时,person的addr属性也被修改了,这是因为遇到对象属性,该方法实际上还是拷贝的对象属性的地址,显然不是我们希望的结果。
我们希望拷贝的是对象,而不是地址,这就是深拷贝。
深拷贝有三种方式可以实现:
- 通过递归实现。
- 通过Lodash库中的
cloneDeep()方法实现。 - 通过
JSON.stringify()方法实现。
递归实现
遍历对象中的属性,如果遇到对象类型就递归拷贝:
1 | // 声明一个person |
cloneDeep() 实现
可以通过第三方库Lodash中的cloneDeep()函数实现:
Lodash库地址:Lodash 简介 | Lodash中文文档 | Lodash中文网
node环境下载Lodash库:
npm i --save lodash
1 | // Load the full build. |
JSON.stringify() 实现
首先利用JSON.stringify()把 person对象转换为JSON字符串,然后再利用JSON.parse()将字符串重新解析为JOSN,并赋给新对象:
1 | // 声明一个person |
this 关键字
关于 this
普通函数
如果是普通函数中的this,它的指向遵循一个原则:谁调用了函数,那么函数中的this就指向谁。
1 | // 普通函数 |
注:
- 在node环境中,最外层的是
global- 在浏览器中,最外层的是
window
箭头函数
事实上箭头函数并不存在this,箭头函数中访问的 this 不过是箭头函数所在作用域的 this 变量。
1 | // 普通箭头函数(函数表达式) |
注:
- 在node环境中,
this指向为空- 在浏览器中,
this指向为window
改变 this 指向
事实上在JavaScript中允许指定函数中this的指向,有三种方法可以动态指定普通函数中this的指向,分别为:call()、apply()、bind()方法。
call()
普通函数可以通过调用call()方法改变this指向,语法如下:
fun.call(thisArg, arg1, arg2, ...)
thisArg:在fun函数运行时指定的this值arg1,arg2,...:传递的其他参数- 返回值就是fun函数的返回值,它就是调用函数
1 | function eat(foodOne, foodTwo) { |
输出如下:
1 | { name: '猫猫' } |
apply()
普通函数可以通过调用apply()方法改变this指向,语法如下:
fun.apply(thisArg, [argsArray])
thisArg:在fun函数运行时指定的this值[argsArray]:传递的参数,必须以数组形式传入,但是fun函数本身的形参并非数组形式- 返回值就是fun函数的返回值,它就是调用函数
1 | function eat(foodOne, foodTwo) { |
输出如下:
1 | { name: '猫猫' } |
bind()
普通函数可以通过调用bind()方法改变this指向,语法如下:
fun.bind(thisArg, arg1, arg2, ...)
thisArg:在fun函数运行时指定的this值arg1,arg2,...:传递的其他参数- 不同于
call()和apply()方法,bind()方法并不会调用函数,而是创建一个指定了this值的新函数。因此返回值为由指定的this值和初始化参数改造的原函数拷贝(新函数)
1 | function food(foodOne, foodTwo) { |
输出如下:
1 | { name: '狗狗' } |
bind()是最常用的方法。可以理解为bind()方法就是创建了一个新函数,与原函数唯一的变化就是改变了this指向。
 微信
微信 支付宝
支付宝